기존 강의 내용 복습
현재 시스템 날짜 출력하기
SELECT SYSDATE FROM DUAL;
현재 날짜에서 크리스마스까지 남은 날짜 구하기
1 2 | SELECT SYSDATE - TO_DATE('23/12/25', 'YY/MM/DD') FROM DUAL; | cs |
크리스마스 날짜를 앞으로 하여 시스템 날짜를 빼면 양수로 출력
입사일이 85년 6월 1일보다 늦은 사람 구하기
1 2 | SELECT * FROM EMP WHERE HIREDATE > TO_DATE('85/06/01'); | cs |
부서번호가 30인 사람의 수 구하기
1 2 | SELECT COUNT(*) FROM EMP WHERE DEPTNO = 30; | cs |
부서번호 별 급여 최댓값 구하기
SELECT DEPTNO, MAX(SAL)
FROM EMP
GROUP BY DEPTNO;
급여가 2,000 이상인 사람들 중 부서번호 별 급여의 평균 구하기
1 2 3 4 | SELECT DEPTNO, AVG(SAL) FROM EMP WHERE SAL >= 2000 GROUP BY DEPTNO ORDER BY DEPTNO; | cs |
직업 별 인원의 수와 인원이 3명 이상인 행만 출력
1 2 3 | SELECT JOB, COUNT(*) FROM EMP GROUP BY JOB HAVING COUNT(*) >=3; | cs |
'SCOTT' 사원의 직업과 근무지 출력
1 2 3 | SELECT E.ENAME, E.JOB, D.LOC FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND E.ENAME='SCOTT'; | cs |
비등가 조인 예시
EMP 테이블의 급여에 GRADE 항목을 같이 출력
SELECT * FROM EMP E, SALGRADE S
WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL;
급여가 1400 이상인 사원의
이름, 직책, 급여, 급여 등급, 근무지 출력하기
SELECT E.ENAME, E.JOB, E.SAL, S.GRADE, D.LOC
FROM EMP E, SALGRADE S, DEPT D
WHERE E.SAL >=1400 AND
E.SAL BETWEEN S.LOSAL AND S.HISAL
AND E.DEPTNO = D.DEPTNO;
급여가 1400 이상인 사원의
이름, 직책, 매니저 이름 출력
SELECT E.ENAME, E.JOB, E2.ENAME
FROM EMP E, EMP E2
WHERE E.MGR = E2.EMPNO(+)
AND E.SAL >= 1400;
서브 쿼리 예시
'SCOTT' 사원보다 급여를 많이 받는 사람의 이름
SELECT ENAME FROM EMP
WHERE SAL > (SELECT SAL FROM EMP
WHERE ENAME = 'SCOTT');
급여를 가장 많이 받는 사람의 이름과 급여 값 출력
SELECT ENAME, SAL FROM EMP
WHERE SAL = (SELECT MAX(SAL) FROM EMP);
부서 별 급여를 가장 많이 받는 사원의 이름과 급여 값 출력
SELECT DEPTNO, ENAME, SAL
FROM EMP
WHERE SAL IN (SELECT MAX(SAL) FROM EMP
GROUP BY DEPTNO);
뷰 생성하기
|
1
2
3
|
CREATE VIEW VM_EMP30ALL
AS (SELECT * FROM EMP
WHERE DEPTNO = 30);
|
cs |
EMP 테이블의 부서번호가 30인 값만 뷰로 생성
|
1
2
|
CREATE VIEW [뷰 이름]
AS [생성될 뷰 조건]
|
cs |
뷰 삭제
DROP VIEW VM_EMP30ALL;
-- DROP VIEW 명령어를 사용하여 생성되어 있는 뷰 삭제
DROP VIEW [뷰 이름]
ROWNUM 명령어DB 데이터를 출력할 때 데이터 순서에 맞게 숫자를 출력해 줌
SELECT ROWNUM, EMP.*
FROM EMP;
예시 1
SELECT ROWNUM, ENAME, JOB, SAL
FROM EMP
ORDER BY SAL;
기본적으로 데이터에 행 번호가 지정되어 있어 정렬을 할 경우 번호가 뒤섞임

SELECT ROWNUM, E.*
FROM (SELECT ENAME, JOB, SAL
FROM EMP
ORDER BY SAL) E;
SAL 값을 기준으로 정렬을 한 테이블을 서브 쿼리로 불러와 그 값에 ROWNUM 을 붙여 정렬하는 방법
다르게 설정할 수 있는 방법은 없음

|
1
2
3
4
5
|
SELECT ROWNUM, E.*
FROM (SELECT ENAME, JOB, SAL
FROM EMP
ORDER BY SAL DESC) E
WHERE ROWNUM <= 5;
|
cs |
정렬 값에 DESC 명령어를 넣어 급여 상위 5명을 확인, ASC 명령어를 이용하여 급여 하위 5명도 확인 가능
시퀀스 (sequence)
시퀀스는 오라클 데이터베이스에서 특정 규칙에 맞는 연속 숫자를 생성하는 객체
시퀀스 생성하기
|
1
2
3
4
5
6
7
|
CREATE SEQUENCE SEQ_DEPT
INCREMENT BY 5
START WITH 50
MAXVALUE 70
NOMINVALUE
CYCLE
NOCACHE;
|
cs |
시퀀스 이름은 SEQ_DEPT 로 지정
값이 5 씩 증가하며, 시작 숫자는 50 으로 설정
숫자의 최댓값은 70, 최솟값은 지정하지 않음
값이 최댓값을 넘어설 때 순환화도록 설정
값을 캐시에 할당하지 않음
CREATE SEQUENCE [시퀀스명]
INCREMENT BY [증감숫자] --증감숫자가 양수면 증가 음수면 감소 디폴트는 1
START WITH [시작숫자] -- 시작숫자의 디폴트값은 증가일때 MINVALUE 감소일때 MAXVALUE
MINVALUE [최솟값] OR NOMINVALUE-- NOMINVALUE : 디폴트값 설정, 증가일때 1, 감소일때 -1028
-- MINVALUE : 최소값 설정, 시작숫자와 작거나 같아야하고 MAXVALUE보다 작아야함
MAXVALUE [최댓값] OR NOMAXVALUE -- NOMAXVALUE : 디폴트값 설정, 증가일때 1027, 감소일때 -1
-- MAXVALUE : 최대값 설정, 시작숫자와 같거나 커야하고 MINVALUE보다 커야함
CYCLE OR NOCYCLE --CYCLE 설정시 최대값에 도달하면 최소값부터 다시 시작 NOCYCLE 설정시 최대값 생성 시 시퀀스 생성중지
CACHE OR NOCACHE --CACHE 설정시 메모리에 시퀀스 값을 미리 할당하고 NOCACHE 설정시 시퀀스값을 메로리에 할당하지 않음
시퀀스 사용
INSERT INTO DEPT_TEMP (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT.NEXTVAL, 'SALES', 'SEOUL');
DEPTNO 값은 시퀀스의 다음 값으로 넣으면서 지정한 DNAME, LOC 값 추가
시퀀스의 다음 값은 [시퀀스 이름].NEXTVAL 명령어 사용
시퀀스 수정
ALTER SEQUENCE [시퀀스명]
INCREMENT BY [증가값]
NOMINVALUE OR MINVALUE [최솟값]
NOMAXVALUE OR MAXVALUE [최대값]
CYCLE OR NOCYCLE [사이클 설정 여부]
CACHE OR NOCACHE [캐시 설정 여부]
CREATE 와 비슷하지만 시작 숫자는 설정하지 않음
시퀀스 삭제
DROP SEQUENCE SEQ_DEPT;
DROP SEQUENCE [시퀀스 이름] 명령어로 시퀀스 삭제
DROP SEQUENCE SEQ_DEPT;
DROP SEQUENCE [시퀀스 이름] --명령어로 시퀀스 삭제
SYNONYM / 동의어
SYNONYM 은 테이블, 뷰, 시퀀스 등 원하는 객체 이름 대신 ALIAS, 별칭을 등록
원래 이름이 너무 길어 불편할 경우 좀 더 간단하고 짧은 이름을 하나 더 만들어 주기 위해 사용
SYNONYM 을 생성하기 위해서는 권한이 있어야 함
GRANT CREATE PUBLIC SYNONYM TO SCOTT;
SCOTT 유저에게 PUBLIC SYNONYM 을 생성할 수 있는 권한 부여
SYNOYNM 생성하기
CREATE SYNONYM E
FOR EMP; : EMP 테이블의 별칭을 E 로 사용
CREATE SYNONYM [별칭] FOR [객체 이름] -- 해당 명령어로 사용
SYNONYM 삭제하기
DROP SYNONYM [이름]
제약 조건 / CONSTRAINT 의 종류
NOT NULL : 지정할 열에 NULL 값을 허용하지 않음. NULL을 제외한 데이터의 중복은 허용
UNIQUE : 지정한 열이 중복된 값을 가지는게 아닌 유일한 값을 가져야 함. NULL 은 값의 중복에서 제외
PRIMARY KEY : 지정한 열이 유일한 값이면서 NULL 을 허용하지 않음. PRIMARY KEY 는 테이블에 하나만 가능
FOREIGN KEY : 다른 테이블의 열을 참조하여 존재하는 값만 입력
CHECK : 설정한 조건식을 만족하는 데이터만 입력 가능
FOREIGN KEY 지정하기
CREATE TABLE [테이블 이름] (
... ,
[열 이름] [열 자료형] CONSTRAINT [제약 조건 이름] REFERENCES [참조 테이블] (참조할 열)
);
포레인 키를 삭제하기 위해서는 키와 연결된 모든 항목을 수정 또는 삭제해야만 기준으로 삼은 FOREIGN KEY 를 삭제할 수 있다.
CHECK 제약 조건은 열에 저장할 수 있는 값의 범위나 패턴을 정의
CREATE TABLE TABLE_CHECK (
LOGIN_ID VARCHAR2(20) CONSTRAINT TBLCK_LOGINID_PK PRIMARY KEY,
LOGIN_PWD VARCHAR2(20) CONSTRAINT TBLCK_LOGINPW_CK CHECK (LENGTH(LOGIN_PWD) > 3),
TEL VARCHAR2(20)
);
LOGIN_ID 열은 PRIMARY KEY 로 설정하고
LOGIN_PWD 열은 열의 값이 3글자를 초과하는 값만 등록할 수 있도록 등록 값에 조건을 걺
데이터 모델링
현 세계에서 사용되는 것들을 DBMS 의 데이터베이스 개체로 옮기는 과정
개념적 데이터 모델링
현 세계의 중요 데이터를 추출하여 개념 세계로 옮기는 작업
논리적 데이터 모델링
개념 세계의 데이터를 데이터베이스에 저장하는 구조로 표현하는 작업
개체 (Entity)
사람이나 사물과 같이 현실 세계에서 조직을 운영하는 데 필요한 구별되는 모든 것
다른 개체와 구별되는 이름을 가지고 있고, 각 개체만의 고유한 특성이나 상태, 즉 속성을 하나 이상 가지고 있음
ex) 서점에 필요한 개체 : 고객, 책
학교에 필요한 개체 : 학과, 과목

속성 (Attribute)
개체나 관계가 가지고 있는 고유의 특성
의미 있는 데이터의 가장 작은 논리적 단위
파일 구조의 필드(field)와 대응됨

단일 값 속성 (Single-Valued)
값을 하나만 가질 수 있는 속성
ex) 고객 개체의 이름, 적립금 속성
다중 값 속성 (Multi-Valued)
값을 여러 개 가질 수 있는 속성
ex) 고객 개체의 연락처 속성 (여러 곳)
책 개체의 저자 속성 (공동 저자)

단순 속성 (Simple Attribute)
의미를 더는 분해할 수 없는 속성
ex) 고객 개체의 적립금 속성
책 개채의 이름, 가격 속성
복합 속성 (COmposite Attribute)
의미를 분해할 수 있는 속성
ex) 고객 개체의 주소 속성 - 도, 시 , 동, 우편번호 등으로 세분화 할 수 있음
고객 개체의 생년월일 속성 - 연, 월, 일로 세분화 할 수 있음
유도 속성 (Derived Attribute)
기존의 다른 속성의 값에서 유도되어 결정되는 속성
- 값이 별도로 저장되지 않음
ex) 책 개체의 가격과 할인율 속성으로 계산되는 판매 가격 속성
고객 개체의 출생연도 속성으로 계산되는 나이 속성

키 속성 (Key Attribute)
각 개체 인스턴스를 식별하는데 사용되는 속성
모든 개체 인스턴스의 키 속성 값이 다름
둘 이상의 속성으로 구성되기도 함
ex) 고객 개체의 고객 아이디 속성
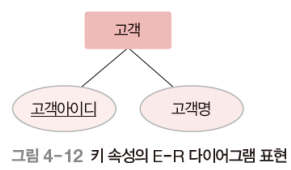
관계 (RelationShip)
개체와 개체가 맺고 있는 의미 있는 연관성
개체 집합들 사이의 대응 관계, 매핑(Mapping)을 의미
ex) 고객 개체와 책 개체 간의 구매 관계
- 고객은 책을 구매한다

관계의 종류
매핑 카디널러티 (Mapping Cardinality) : 관계를 맺는 두 개체 집합에서, 각 개체 인스턴스가 연관성을 맺고 있는 상대 개체 집합의 인스턴스 개수
개체 인스턴스 (Entity Instance) : 개체를 구성하고 있는 속성이 실제 값을 가짐으로써 실체화된 개체
1 : 1 관계
개체 A 의 각 개체 인스턴스가 개체 B 의 인스턴스 하나와 관계를 맺을 수 있음
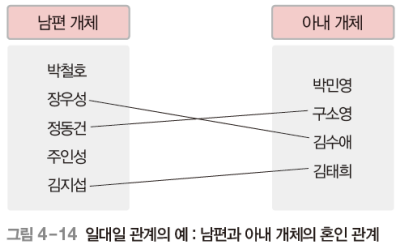
1 : n 관계
개체 A 의 인스턴스가 개체 B 의 인스턴스 여러 개와 관계를 맺을 수 있지만, 개체 B 의 인스턴스는 개체 A 인스턴스 하나와 관계를 맺을 수 있음

다 대 다 관계
개체 A 의 인스턴스가 개체 B 의 인스턴스 여러 개와 관계를 맺을 수 있음

논리적 데이터 모델링
E-R 다이어그램으로 표현된 개념적 구조를 데이터베이스에 저장할 형태로 표현한 논리적 구조
- 데이터베이스의 논리적 구조 = 데이터베이스 스키마(Schema)
- 스키마는 데이터베이스를 지칭하는 것으로 보면 됨
사용자가 생각하는 데이터베이스의 모습 또는 구조
논리적 데이터 모델링의 종류 : 관계 데이터 모델, 계층 데이터 모델, 네트워크 데이터 모델 등
관계 데이터 모델
개념적 구조를 논리적 구조로 표현하는 논리적 데이터 모델
하나의 개체에 대한 데이터를 하나의 릴레이션에 저장
데이터베이스의 논리적 구조가 2차원 테이블 형태
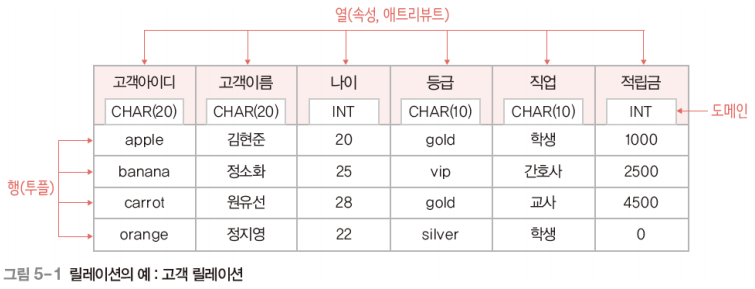
릴레이션의 특징
투플의 유일성
- 하나의 릴레이션에서는 동일한 투플이 존재할 수 없다
투플의 무순서
- 하나의 릴레이션에서 투플 사이의 순서는 무의미하다
속성의 무순서
- 하나의 릴레이션에서 속성 사이의 순서는 무의미하다
속성의 원자성
- 속성 값으로 원자 값만 사용할 수 있다 // * 원자 값 : 더 이상 나눌 수 없는 값
키 (Key)
릴레이션에서 투플들을 유일하게 구별하는 속성 또는 속성들의 집합
키의 특성
유일성 (Uniqueness)
- 하나의 릴레이션에서 모든 투플은 서로 다른 키 값을 가져야 함
최소성 (Minimality)
- 꼭 필요한 최소한의 속성들로만 키를 구성
키의 종류
슈퍼키 (Super Key)
유일성을 만족하는 속성 또는 속성들의 집합
ex) 고객 릴레이션의 슈퍼키 : 고객 아이디, (고객 아이디, 고객 이름), (고객 이름, 주소) 등
기본키 (Primary Key)
후보키 중 기본적으로 사용하기 위해 선택한 키
ex) 고객 릴레이션의 기본키 : 고객 아이디
후보키 (Candidate Key)
- 유일성과 최소성을 만족하는 속성 또는 속성들의 집합
ex) 고객 릴레이션의 후보키 : 고객 아이디, (고객 이름, 주소) 등
대체키 (Alternate Key)
기본키로 선택되지 못한 후보키
ex) 고객 릴레이션의 대체키 : (고객 이름, 주소)

외래키 (Foreign Key)
다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
릴레이션들 간의 관계를 표현

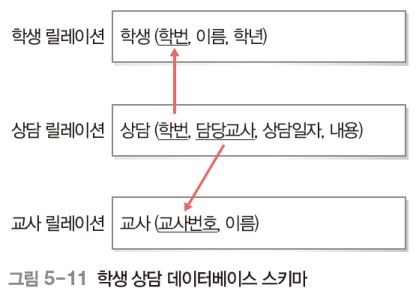
같은 릴레이션의 기본키를 참조하는 외래키도 정의할 수 있음

'SQL' 카테고리의 다른 글
| 240202 리눅스 서버 만들어보기 (0) | 2024.02.02 |
|---|---|
| 231129 Oracle (1) | 2023.11.29 |
| 231128 Oracle (0) | 2023.11.28 |
| 국비지원학원 3, 4일 차 정리 / ORACLE (0) | 2023.11.26 |
| 국비지원학원 1,2일 차 정리 / ORACLE (0) | 2023.11.24 |
